DMV3D:Denoising Multi-View Diffusion
using 3D Large Reconstruction Model
Abstract
We propose DMV3D, a novel 3D generation approach that uses a transformer-based 3D large
reconstruction model to denoise multi-view diffusion.
Our reconstruction model incorporates a triplane NeRF representation and can denoise noisy multi-view
images via NeRF reconstruction and rendering, achieving single-stage 3D generation in 30s
on single A100 GPU.
We train DMV3D on large-scale multi-view image datasets of highly diverse objects using
only image reconstruction losses, without accessing 3D assets.
We demonstrate state-of-the-art results for the single-image reconstruction problem where probabilistic
modeling of unseen object parts is required for generating diverse reconstructions with sharp textures. We
also show high-quality text-to-3D generation results outperforming previous 3D diffusion models.
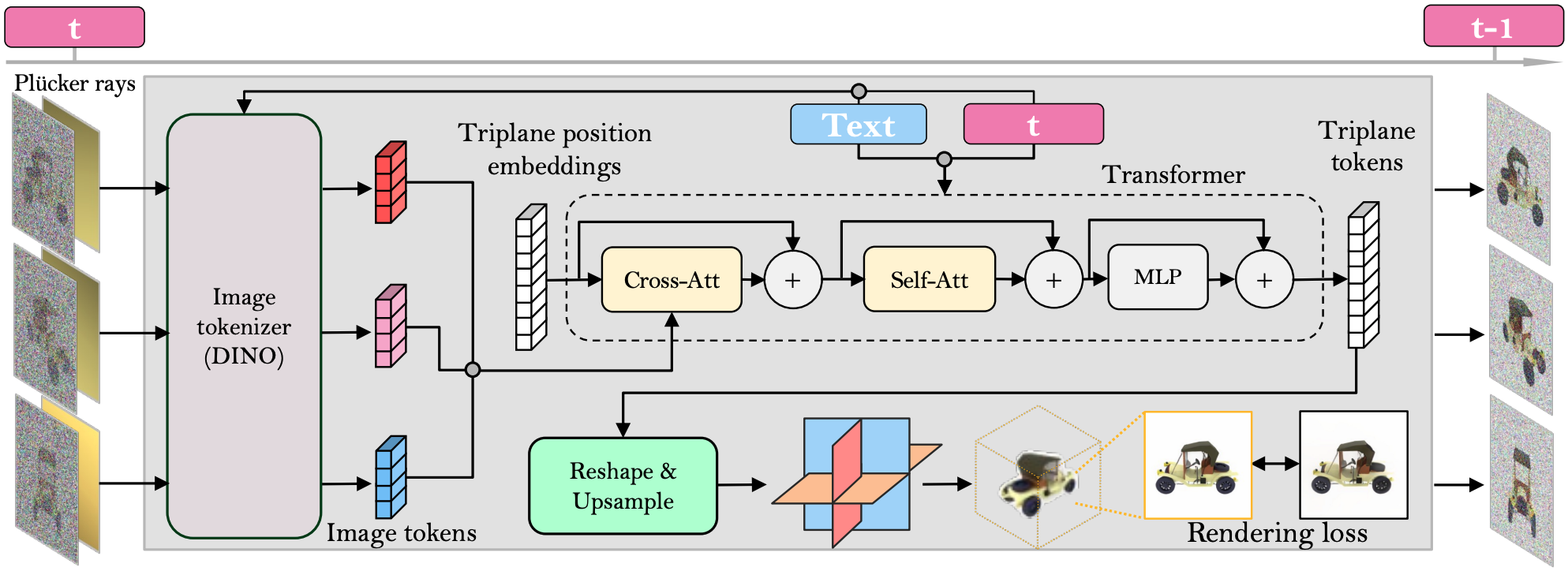
Framework. We denoise multiple views (three shown in the figure; four used in experiments) for 3D generation. Our multi-view denoiser is a large transformer model that reconstructs a noise-free triplane NeRF from input noisy images with camera poses (parameterized by Plucker rays). During training, we supervise the triplane NeRF with a rendering loss at input and novel viewpoints. During inference, we render denoised images at input viewpoints and combine them with noise to obtain less noisy input for the next denoising step. Once the multi-view images are fully denoised, our model offers a clean triplane NeRF, enabling 3D generation.
Image-to-3D
BibTeX
@misc{xu2023dmv3d,
title={DMV3D: Denoising Multi-View Diffusion using 3D Large Reconstruction Model},
author={Yinghao Xu and Hao Tan and Fujun Luan and Sai Bi and Peng Wang and Jiahao Li and Zifan Shi and Kalyan Sunkavalli and Gordon Wetzstein and Zexiang Xu and Kai Zhang},
year={2023},
eprint={2311.09217},
archivePrefix={arXiv},
primaryClass={cs.CV}
}